
在AIoT(人工智能物联网)边缘计算场景中,硬件算力是基础,而软件生态的成熟度决定了产品的落地速度与应用广度。杰和科技LM2-100-V0算力模组作为一款搭载M1M NPU高性能计算单元,其核心优势不仅在于芯片本身的高能效比,更在于其完善的软件栈适配体系。本文将结合《NPU软件生态介绍》及架构图,详细剖析基于LM2-100-V0的NPU软件适配全流程。

从整体架构来看,NPU软件适配分为两个核心阶段:AI模型编译环境(AI Model Compile Environment)与AI模型运行时环境(AI Model Runtime Environment)。这种分离式设计确保了模型从开发到部署的高效转化。
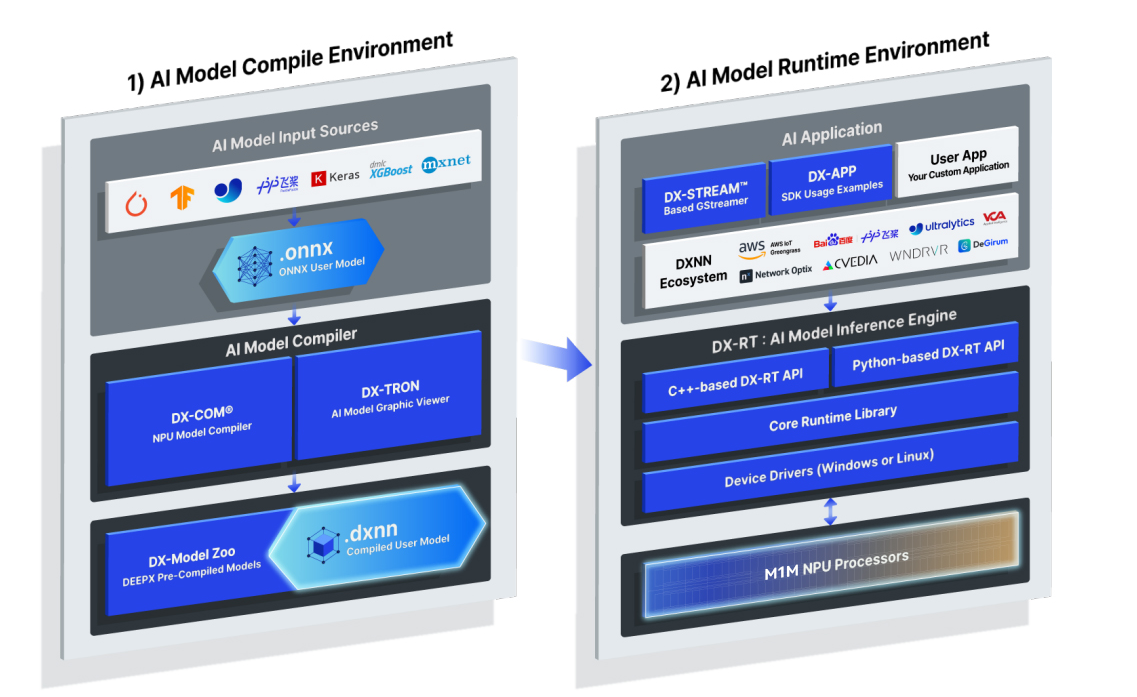
在LM2-100-V0上运行AI应用的第一步,是将开发者手中的原始模型转化为NPU可识别的中间格式。此阶段主要在开发主机(通常是x86架构的Linux或Windows PC)上完成。
模型输入源(AI Model Input Sources)
LM2-100-V0的软件栈具备极高的兼容性,支持主流深度学习框架导出的模型。无论是PyTorch、TensorFlow、Keras,还是飞桨PaddlePaddle、MXNet、XGBoost,均可作为输入源。这意味着开发者无需重写算法,直接利用现有资产即可开始适配。
模型统一化:ONNX转换
为了打破框架壁垒,流程中引入了ONNX(Open Neural Network Exchange)作为开放的模型表示标准。所有输入模型首先被转换为ONNX格式,形成标准的“ONNX User Model”。这一步骤是跨平台、跨硬件适配的关键节点。
核心编译:DX-COM® 与 DX-TRON
在编译环境中,核心工具是DX-COM®(NPU Model Compiler),它负责将ONNX模型进行图层解析、优化和指令集映射,生成NPU专属的二进制模型。同时,DX-TRON作为图形化查看器,允许开发者直观检查模型结构,确保转换过程中的准确性。
输出模型库(DXNN Compiled User Model)
编译完成后,模型被封装为dxnn格式。LM2-100-V0不仅支持自定义模型转换,也直接支持调用库中已验证的主流视觉模型,如ResNet50、YOLO系列、MobileNetV2等,极大缩短了开发周期。
编译好的模型需要在LM2-100-V0硬件本体上运行,这依赖于其强大的运行时环境(Runtime Environment)。
底层驱动与核心库
运行时环境的最底层是Device Drivers,支持Windows或Linux双系统,确保LM2-100-V0能灵活嵌入不同操作系统生态。向上是Core Runtime Library,提供核心计算支持。
推理引擎:DX-RT
核心组件DX-RT(AI Model Inference Engine)是整个运行时环境的大脑。它提供了多种API接口以降低开发门槛:
C++-based DX-RT API:面向高性能、低延迟的工业级应用。
Python-based DX-RT API:面向快速原型开发和算法验证,契合当前AI开发主流习惯。生态应用与集成
在DX-RT之上,构建了DXNN Ecosystem。LM2-100-V0支持接入多种第三方工具与中间件,如Network Optix(视频分析)、CVEDIA(汽车视觉)、WNDRVR等,同时也支持aWS、BaoGuan、ultralytics等解决方案。开发者可以通过DX-APP或DX-STREAM构建具体应用,最终无缝集成到用户的自定义应用(User App)中。
基于上述流程,杰和科技LM2-100-V0算力模组展现了极具竞争力的软件适配能力:
全链路闭环:从模型输入到最终推理,提供了完整的工具链支持。
高兼容性与易用性:通过ONNX标准与多框架支持,降低迁移成本;通过C++/Python双接口,满足不同开发者需求。
生态丰富:内置DX-Model Zoo与DXNN Ecosystem,让开发者既能用现成方案,也能跑自己的私有模型。

在边缘AI设备日益复杂的今天,LM2-100-V0不仅是一块算力模块,更是一个开箱即用的NPU软硬一体化计算平台,助力企业快速实现智能化升级。





 杰和公众号
杰和公众号
 杰和视频号
杰和视频号



















